
Project Team member: Youngwoong Cho, Kenny Huang, Miho Takeuchi, Andrew Lam
This project is submitted to COOPER UNION END OF YEAR SHOW 2021.
Introduction
Can we ask a neural network to compose a music from a video?
When watching a video of a brilliant scenery or a cute dog playing with a ball, we, humans, sometimes experience a beautiful melody playing by itself in our heads. We are unconsciously translating a video, or a sequence of images, into a music. Would it be possible for a neural network to compose a melody from a video input?
A deep neural network was trained to generate a sequence of MIDI notes from a video input. It consists of two subparts, one for the object detection, and another for the generation of a melody.
YOLO algorithm is used for the object detection. YOLO algorithm predicts a bounding box corresponding to each objects detected from the image. The parameters for the bounding boxes, such as the type of the object, $x$ and $y$ value, width, and height of the bounding box, are used as the “ingredients” for the generation of the primer melodies.
After generating the primer melody, lookback-RNN is used to continue the melody. Here’s where the “composition” is happening.
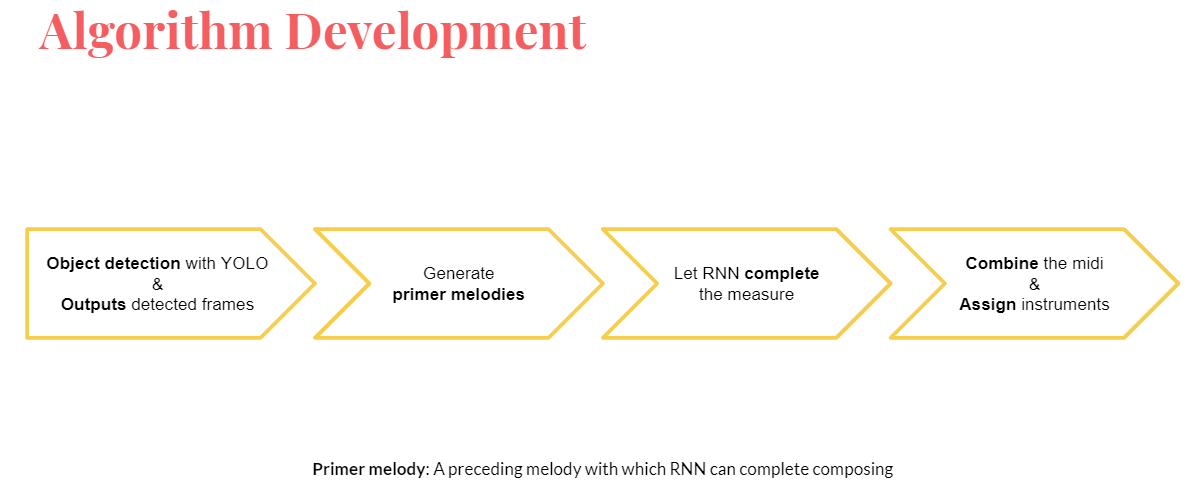
Process
Problem definition
The goal of the project is to create a neural network model that is capable of translating the video input, or a sequence of image input, $ \{ I_i | I_i \in \mathbb{R}^{3 \times H \times W} \}_i $, to a MIDI output $ \{ M_j | M_j \in \mathbb{Z}^{2 \times \left(8 \times \text{beat number} \right) \times 16} \}_j $.
Object detection
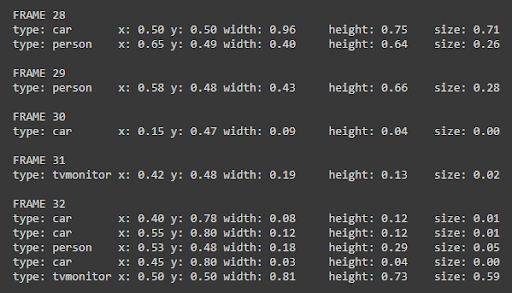
YOLO (You Only Look Once) is an algorithm for an object detection. For a given image input, it outputs a set of bounding boxes that dictate the position and size of the objects along with the class of the object.

Next, we retreive the parameters of each bounding box. We extracted the type of the objects, relative positions of the center of the bounding boxes ($x_{\text{rel}}=\frac{x}{\text{image width}}$, $y_{\text{rel}}=\frac{y}{\text{image height}}$), and the relative size of the bounding box ($w_{\text{rel}}=\frac{w}{\text{image width}}$, $h_{\text{rel}}=\frac{h}{\text{image height}}$).
Primer melody generation
We mapped the parameters extracted from the previous step into a MIDI domain to generate the corresponding primer melody. The algorithm for the mapping from the bounding boxes to a primer melody is as follows.
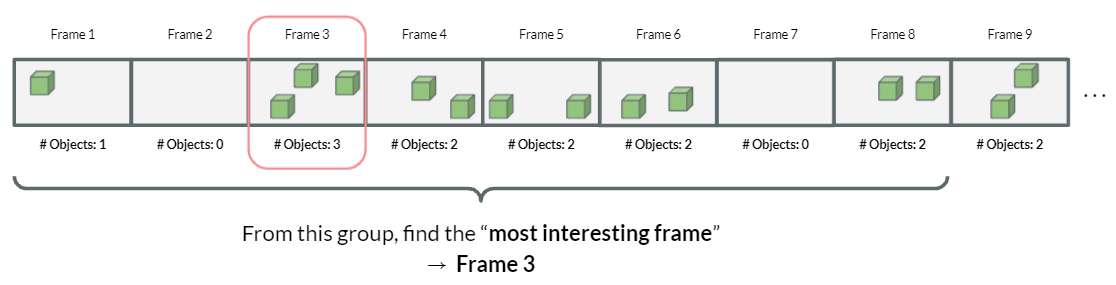
Picking a key-frame
First, we create a group of frames, from which the most interesting frame is selected. Most interesting frame is a frame that has the most number of objects detected, and thus will generate the most number of melodies.
Mapping policy
The total number of the objects is mapped to the number of melody lines. This mapping will allow the model to generate a more complicated and dynamic primer melody from a video with more objects.
The relative $x$ position is mapped to the beat number of the primer melody. If the object is present on the left side of the image, it will result in a melody that will be played first. If the object resides on the right side of the image, it will be mapped into a MIDI note that will be played later.
The relative $y$ position is mapped to the pitch of the primer melody. If the object is at the upper side of the image, it will result in a higher note. Objects from the lower side will produce the lower notes.
The relative size of the object, which is computed as $s_{\text{rel}}=w_{\text{rel}}\times h_{\text{rel}}$, is mapped to the octaves of the primer melody. The bigger the object is, the higher the octave is.
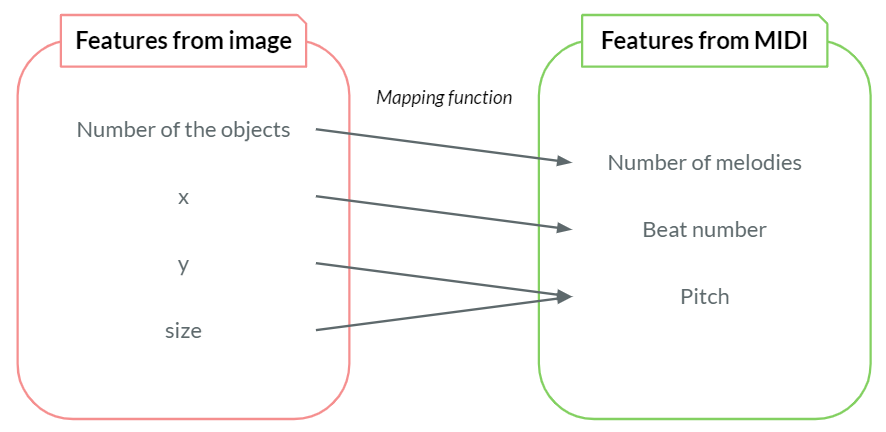
Figure below visualizes how the features from bounding boxes are mapped into the features from MIDI.
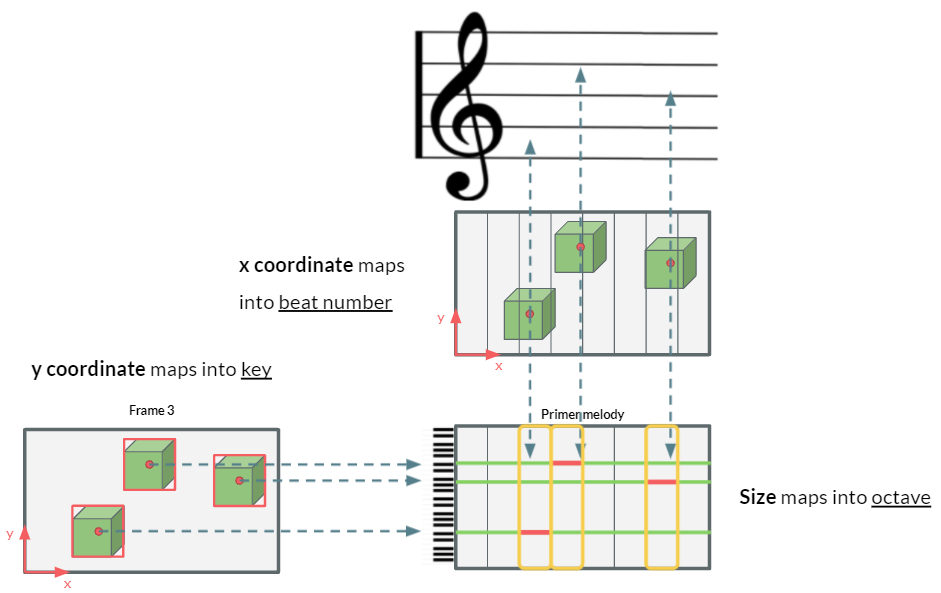
In order to facilitate the primer melody generation process, several constraints were imposed.
- $x$, $y$, and size values are normalized so that they can have values between 0 and 1. In other words, as mentioned previously, the relative values were used.
- Each measure (musical domain) has 8 beats.
- The height of the image is equivalent to 2 octaves.
- Possible keys range from C2 to B7 (6 octaves).
Melody generation
A lookback-RNN algorithm is used to complete the music from the primer melody.
Lookback RNN is an improvement in RNN’s ability to recognize the long-term structure. Lookback RNN introduces custom inputs and labels that help the model recognize patterns related to where in the measure an event occurs.
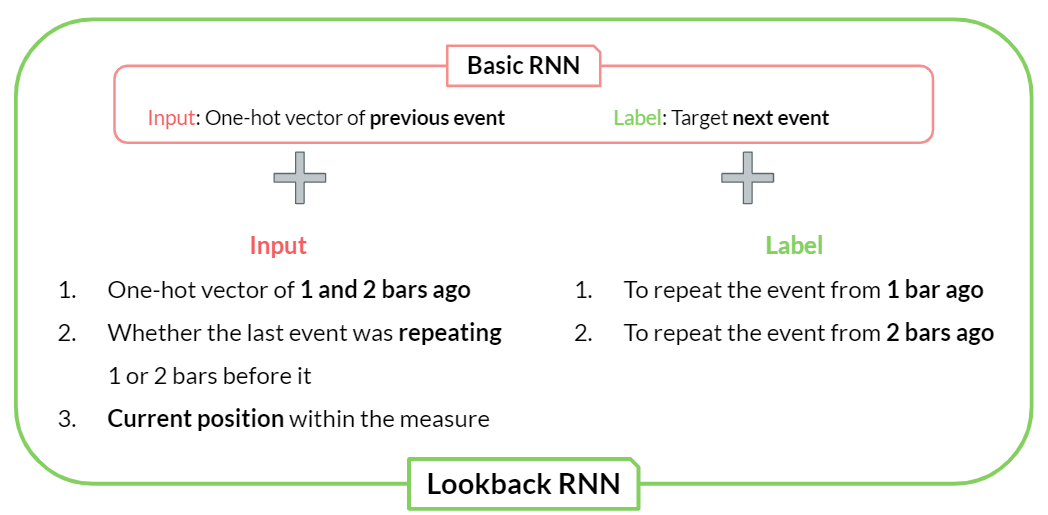
For each melody block, we ask lookback-RNN to generate the number of melodies that is equal to the number of the objects in the most interesting frame.
After the MIDI melodies are generated, we used a Digital Audio Workstation (DAW) to assign the instrument to each melody.
Result
Below is the resulting music generated from the video input.
The code of the project can be found from the following Github link.
Leave a comment